Since launching EvoBlog internally, I’ve wanted to improve it. One way of doing this is having an LLM judge the best posts rather than a static scoring system.
I appointed Gemini 2.5 to be that judge. This post is a result.
The initial system relied on a fixed scoring algorithm. It counted words, checked readability scores, & applied rigid style guidelines, which worked for basic quality control but missed the nuanced aspects of good writing.
What makes one paragraph flow better than another? How do you measure authentic voice versus formulaic content?
EvoBlog now takes a different approach. Instead of static rules, an LLM evaluator scores each attempt across five dimensions: structure flow, opening hook, conclusion impact, data integration, & voice authenticity.
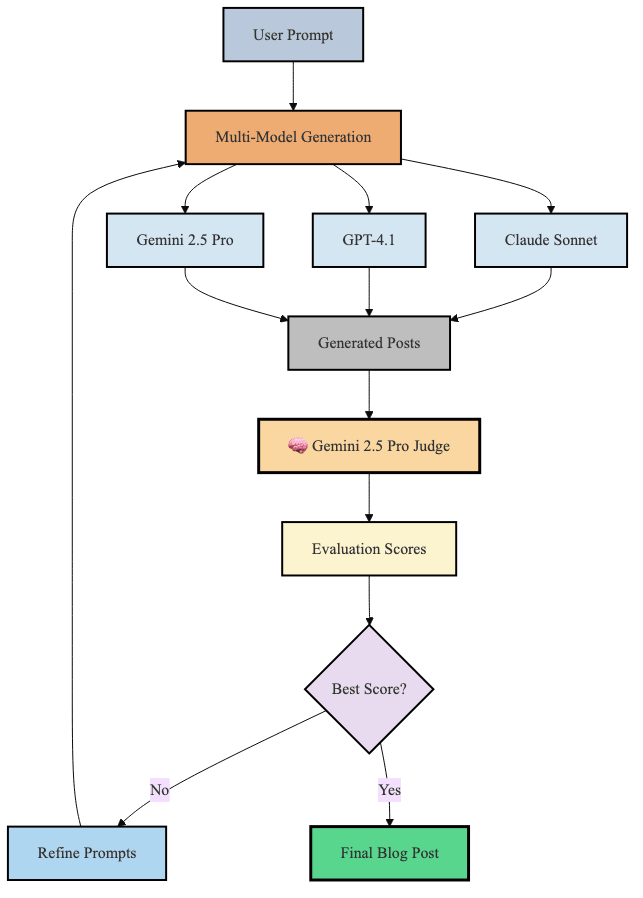
The theory is that magic happens in the iterative refinement cycle.
After each generation round, the system analyzes what worked & what didn’t. Did the opening hook score poorly? The next iteration emphasizes stronger first paragraphs. Was data integration weak?

The LLM judge experiment yielded mixed results. The chart shows swings in performance across 20 iterations, with no clear convergence pattern. The best run achieved 81.7% similarity to my writing style, a 3.1 percentage point improvement over the initial 78.6%.
But the final iteration scored 75.4%, actually worse than where it started.
The LLM as judge sounds like a good idea. But the non-deterministic nature of the generation & the grading doesn’t produce great results.
Plus it’s expensive. Each 20 iteration run requires about 60 LLM calls or about $1 per post. So, maybe not that expensive!
But for now, the AI judge isn’t all that effective. The verdict is in: AI judges need more training before they’re ready for court.