The inference market is the fastest growing market in the world & it’s splitting up. Each modality is developing its own inference stack.
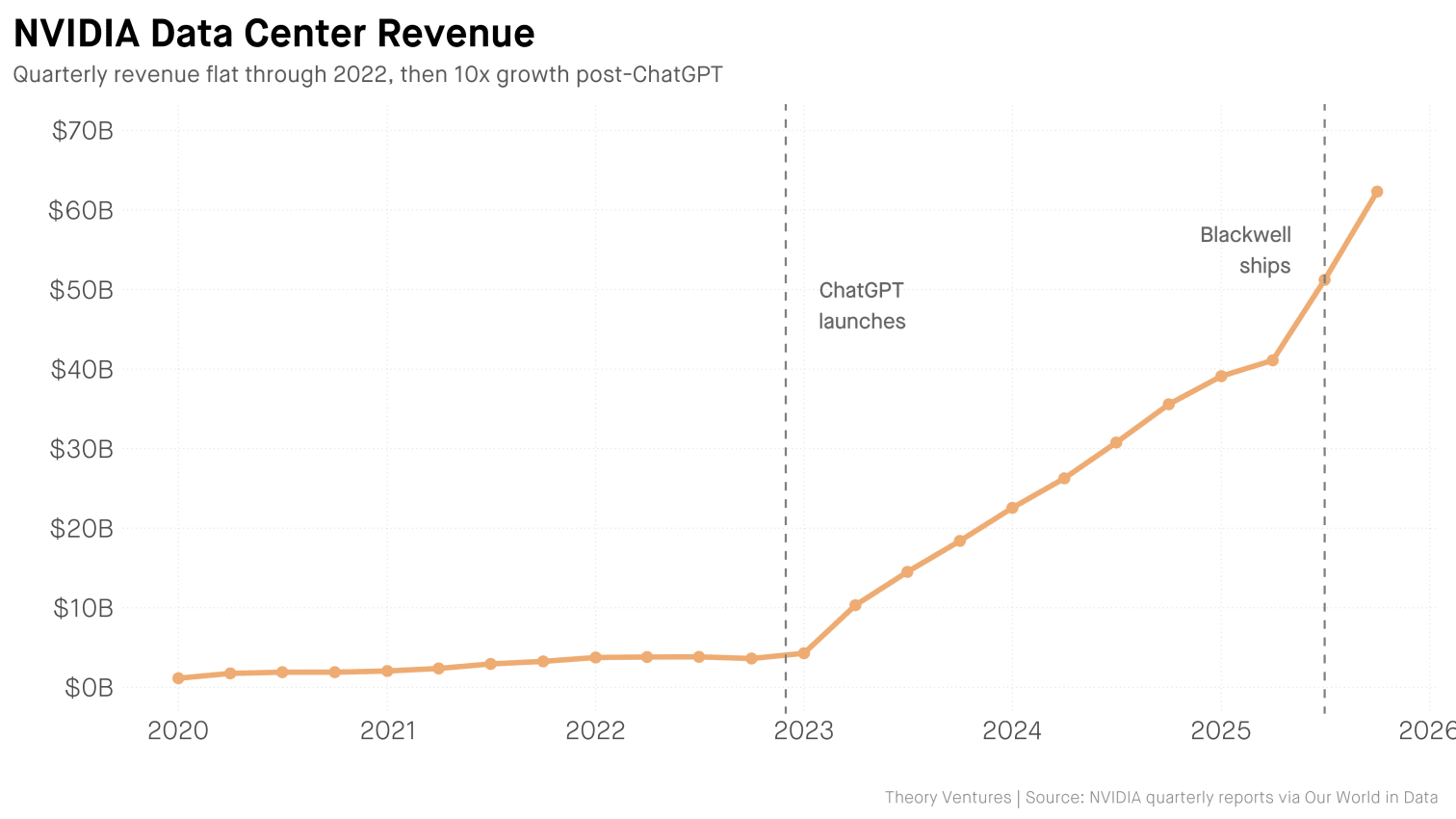
NVIDIA’s data center revenue was flat through 2022. Then ChatGPT launched. Three years later : 17x growth.1
Databases did the same thing. What started as one market fragmented into relational, document, key-value, graph, time series, vector, & others. Each category reflects different workload requirements : real-time transactions vs batch analytics, ACID compliance vs eventual consistency.
The inference market is fragmenting for the same reason : workloads are different. Images & video are compute-heavy. Longer context windows demand more memory for KV cache. Edge devices have power constraints. A single architecture can’t optimize for all of them.
The model ecosystem reflects this. A few dominant LLMs with long half-lives sit alongside 90,000+ image generation models on Hugging Face, with new variants appearing daily.2 Each model type has different serving requirements, which fragments the infrastructure. Today, we see these segments :
Latency Tiers : Real-Time, Near-Real-Time, & Batch
Latency defines three distinct segments. Real-time (sub-100ms) serves voice assistants, live translation, & autonomous vehicles. Users won’t wait, so infrastructure must be geographically distributed with dedicated capacity.
Near-real-time (100ms-2s) covers chatbots, code completion, & search augmentation. Most LLM applications today operate here, where batching & queuing optimize throughput without degrading experience.
Batch (seconds to hours) handles document processing & content generation at scale. Cost efficiency matters more than speed, so workloads run during off-peak hours on spot instances.
Multimodal (Image, Video, Audio)
The bottleneck shifts. For chatbots, the problem is memory. The model holds the entire conversation in its head, & that memory grows with every turn. For image & video generation, the problem is raw compute. A single image requires 50 sequential passes through the model. Different architectures, different constraints, different infrastructure.
Edge (On-Device & On-Premise)
Privacy requirements, connectivity constraints, & latency sensitivity push inference to edge devices. Mobile phones, industrial sensors, medical devices. Apple runs a 3-billion-parameter model on-device for Apple Intelligence. Tesla runs vision models on FSD chips drawing 72 watts. Quantized models, specialized chips, & limited memory create different optimization challenges than cloud inference.
The database market produced Oracle, MongoDB, Databricks, & Snowflake. A $100B inference market3 fragmenting the same way creates room for similar winners.
-
NVIDIA Quarterly Reports - Data center revenue grew from $3.6B (Q4 2022) to $62.3B (Q4 2025). ↩︎
-
Hugging Face Text-to-Image Models - Over 90,000 text-to-image models hosted as of April 2026. ↩︎
-
Grand View Research : AI Inference Market Size 2024 - Estimated at $97.24B in 2024. ↩︎