Most teams building agents pick the model first & the architecture second. That is backwards. The model choice is the last decision, not the first.
What matters is the router, a small piece of code that decides which tier of model handles each request. Get the router right & 70-80% of traffic runs on local models that cost nothing per call, or on async models1 that reduce AI spend by 90%+.
Brian Armstrong made the same point last week about how Coinbase cut AI spend in half while token usage grew2, paraphrasing :
How to keep AI spend flat while token usage grows exponentially : not with friction & spend alerts. With better defaults, routing, & caching. Engineers can choose any model they want, but defaults matter.

The routing problem has three layers, and each does a distinct job :
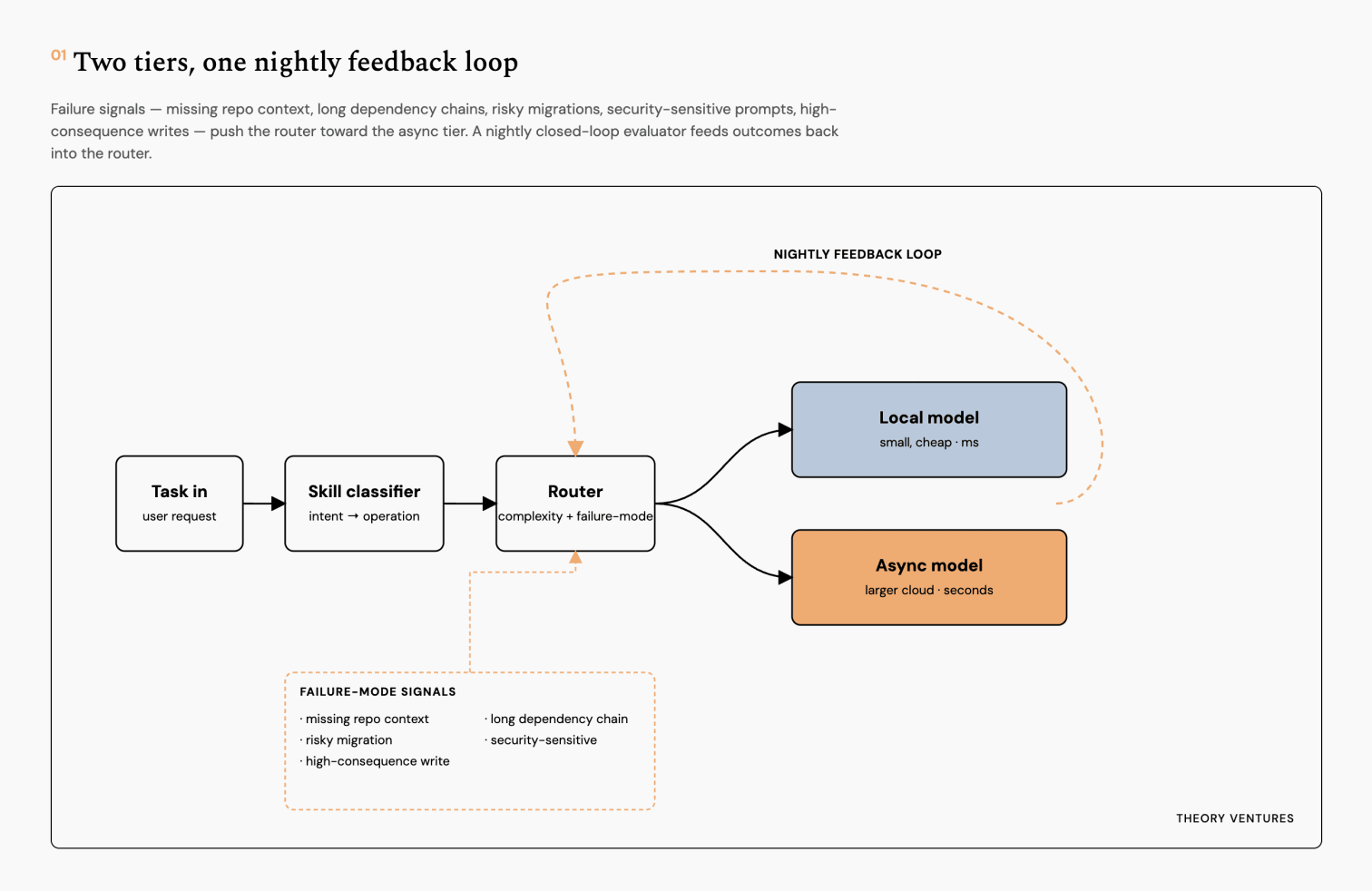
- Skill classifier turns a raw user request into a concrete operation. It answers what the task is. Draft-a-reply, summarize-a-repo, run-a-migration. The classifier is intent recognition.
- Router decides which tier executes the classified operation. It answers which model runs it. The router does not read the prompt. It reads the classifier’s label plus a few features : complexity, context size, historical success rate.
- Model selector picks the cheapest model within a tier that meets a confidence threshold.
Classifier & router are not the same. The classifier is a language problem ; the router is a scheduling problem. Conflating them buries the model choice inside the prompt & kills the ability to A/B different models against the same operation.
Local compute is close to free. Async batch reasoning runs two orders of magnitude cheaper than real-time inference1. So the real question is narrower : what fraction of work needs real-time answers?
Surprisingly little, once the system can queue work.
Queueing is why this works. A draft reply, a repo summary, a diligence memo, a nightly evaluator run : none of these need to return in a second.

We built the first version of this into our agent runtime. The router already scored tasks on complexity, context size, & local memory retrieval. Two feedback mechanisms now sit on top of the router, & they operate on different time scales :
- Synchronous failure-mode signals. A predictor annotates each incoming route with five features : missing repo context, long dependency chains, risky migrations, security-sensitive prompts, & high-consequence writes.
- Nightly closed-loop feedback. A batch evaluator scores yesterday’s traces overnight & updates the router’s weights, running on async inference on Sail to keep the evaluation cost near zero.
The synchronous predictor catches known-hard tasks before they fail. The nightly loop discovers new failure modes the predictor missed.
Once skill distillation flattens the operation set, 70-80% of agent traffic can run on local models3 for most non-coding work.
The implication : design your system around routing, not around models. Pick your models last.
-
Full Sail on Asynchronous Inference — the cost delta between real-time & async batch inference. ↩︎ ↩︎
-
Brian Armstrong on X — Coinbase cut AI spend nearly in half while token usage grew, via better defaults, routing, & caching. ↩︎
-
Skill Distillation, Teaching Local Models to Call Tools Like Claude, & The Minimill of AI. ↩︎