Today, a Hacker News thread asked a simple question : “Has anyone replaced Claude/GPT with a local model for daily coding?”1 500+ comments later, a clear picture emerged of the local coding stack.
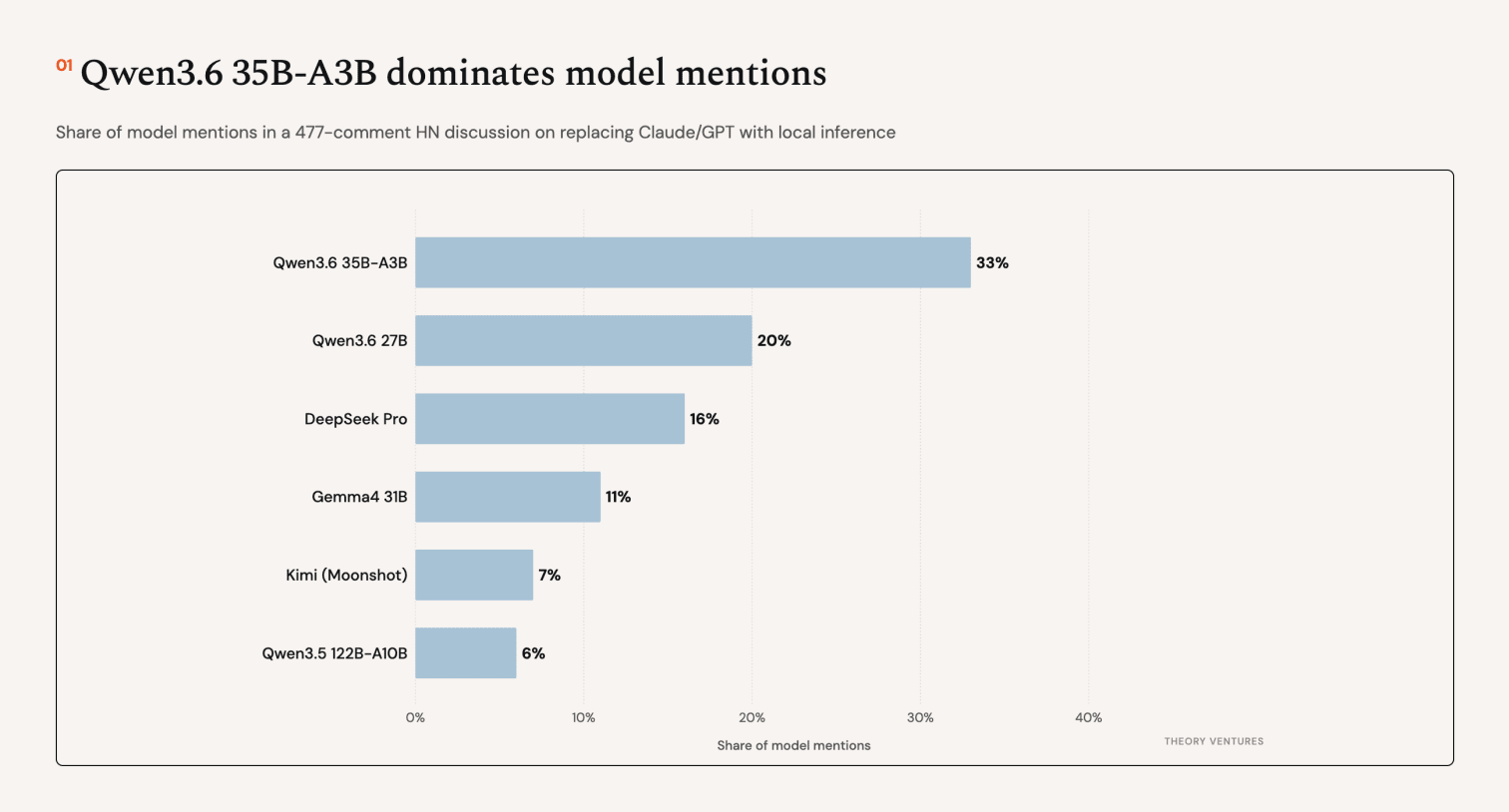
Qwen 3.6 35B-A3B dominates model mentions at 33%, followed by the 27B variant at 20%. DeepSeek Pro & Gemma4 31B round out the top four. The common thread : mixture-of-experts architectures that run fast on consumer hardware.2

On the agent side, Pi leads at 49% with OpenCode close behind at 45%. Both are lightweight harnesses designed for local inference.
The thread surfaced a fascinating tradeoff. One commenter captured it perfectly :
Comparing agentic Qwen3.6 35b to Claude Opus is like a junior with knowledge across the board, that you really need to guide, versus a senior that thinks with you on architecture. If Opus gives a 15x speedup, local and fully offline Qwen gives a 5x speedup.
But for many, the tradeoff is worth it. Privacy, zero cost, & complete offline capability matter.
Given that it’s completely free, is still mind-boggling to me.
The local coding stack is maturing fast. Qwen 3.6 35B-A3B has become the de facto standard & Pi the leading harness.

The benchmark data backs up the sentiment. Qwen3.6 27B scores 77.2% & the MoE variant, Qwen3.6 35B-A3B, hits 73.4%. These two local models are within spitting distance of Claude Sonnet 4.6 (79.6%).3
This is the minimill pattern playing out in real time. It’s not just for CRM updates & web research. The current generation of local models is good enough for reasonable coding tasks.
-
MoE models are large models that only activate a small fraction of their total parameters. Qwen 3.6 35B-A3B has 35 billion total parameters but only 3 billion active at inference time, while the 27B variant runs all 27 billion parameters each time. ↩︎
-
SWE-bench Verified scores from llm-stats.com & morphllm.com, June 2026. ↩︎